The Cleaners

What’s better than a load test application for Hazelcast? Obvious: A load test application for Hazelcast with the ability to clean previously created state before starting a load test, so as to establish a clean cluster as the baseline for each test run.
The cleaners that will be the stars of today’s blog post are, unfortunately, not able to perform the cleaning chores around your place for you, but what they can do for you is cleaning up state in your Hazelcast cluster before a load test starts. Learn why that matters and how exactly it works in the following sections!
Why Cleaning State Matters
We’re going to dive first into why cleaning state is important by establishing the link between side effects and state on one hand, and testability and the value of quickly generating clean state on the other.
Side Effects, State, And Testability
Have you ever heard of a chap called Haskell Curry? No? Well, I hadn’t, either, until I was to write a research paper on the Haskell programming language during my Computer Science studies many, many moons ago. The aforementioned gentleman was an American logician and mathematician, and the Haskell programming language was named after him.
(I would have loved to write a paper on Golang, but another student had already picked that from the list of available languages the professor had put out. When I picked, only two languages were left – one was Haskell, and the other – shudder – JavaScript. Obviously, I took Haskell, which turned out to be a really interesting and powerful programming language.)
Haskell is a purely functional programming language, meaning, in simple terms, it won’t let you do anything that has a side effect in the application itself (even I/O operations such as writing to a file system are neatly tucked away behind a concept called Monads in Haskell). In support of this concept, all functions in Haskell are pure, meaning they are functions in the mathematical sense – given the same input, they will always produce the same output, without acting on, or making modifications to, any kind of application state. Thus, running these functions never has any side effects as far as the application itself is concerned. Programs composed of such functions are typically very reliable and robust because not only does their lack of internal state make them easier to understand, but their testability is usually very good, too – a unit under test that behaves like a pure function (or indeed is a pure function) is a lot easier to test than one that doesn’t.
For example, imagine a function that inserts a new tuple of a user’s name and email into a database, with the email being the primary key. Were the test for this function to actually invoke the database, test execution would not only depend on the availability of an external system – the database –, but also on the state present in that external system (the tuple in the database): Assuming no clean-up functionality in the test and assuming we haven’t implemented our hypothetical function to be idempotent, the test would probably fail the second time it is run because a user with the given email address already exists in the database at that point. So, the external state would act as a kind of hidden input to the function, altering its output. Because this input is implicit, it is neither part of the test definition nor the function invocation itself, so it’s much harder to spot, and to control it would require building some functionality to establish the desired state (or absence thereof) in the external system. Because this would significantly hurt testability, it is no secret that tests, no matter the programming language, should never have side effects on external systems, and, ideally, even side effects in the own program domain are avoided.
By now, you might be asking yourself how all of the above is related to load-testing Hazelcast clusters. Fair enough – let me make an example to establish the link:
When load-testing a new Hazelcast cluster configuration for my client, map set latencies increased dramatically after switching from Hazeltest’s batch loop type to the boundary loop type. This was confusing at first – the input, while not exactly the same due to having changed the test loop type, was still very similar, yet the output (the behavior observable about the target Hazelcast cluster) was vastly different. Checking Hazeltest’s source code, it turned out that a piece of functionality in the boundary test loop relied on state retrieved from the target Hazelcast cluster, and that the retrieval was implemented using an SQL-like statement on the given map or maps to query all keys matching a certain prefix. The query was to be executed only very rarely – at the beginning of each of the boundary test loop’s operation chains –, but if an inconsistency occurred during execution of the operation chain between the local cache thus established and the contents of the target map, then the chain would abort, start anew, and again perform its query to populate the local cache. What I hadn’t considered when writing this functionality is that when the target Hazelcast cluster’s memory capacity is reached, map eviction will kick in, deleting values based on the configured eviction policy. Because the Hazelcast cluster was still filled to the brim from previous test runs, a scenario manifested in which the local cache would frequently run out-of-sync with the state in the target map. Consequently, the boundary test loop just kept restarting its operation chain, essentially flooding the cluster with queries on huge maps. Sure enough, metrics showed a direct relation between an increase in the map query count and an increase in the set latencies. This makes sense: If the map in question isn’t indexed, evaluating all keys in scope of a query for whether they fulfill a given criterion basically halts any key-altering operations for as long as the query is running, and the larger the map, the bigger the impact of this halting of operations – which can show itself, for example, in sharply increased map set latencies. (Of course, the aforementioned functionality in Hazeltest’s boundary test loop has since been fixed, so it doesn’t rely on state queried from the target Hazelcast cluster anymore and so the implementation is more resilient towards cases when the target map experiences evictions.)
What has ultimately caused the difference in output was therefore not only having switched to the boundary test loop, but also the state the target Hazelcast cluster was in when the load test started: Had the cluster been empty, then the observable behavior of the Hazelcast cluster (i.e. the output of the load test) would have been very similar to that of previous load test iterations. So, the side effects of previous load tests contributed significantly to a change in the output of the current load test.
We introduced this section by establishing that functions in Haskell have good testability because they do not create any side effects (they can’t, in fact, at least not within the realm of the program domain itself), and we have explored how side effects can indeed hurt testability no matter the level of abstraction. The conclusion offers itself easily: Side effects during testing should be avoided if at all possible, regardless of whether the thing you’re testing is a piece of code or an entire Hazelcast cluster. This even goes beyond testability – altered output given seemingly identical or very similar input makes it impossible to reasonably compare the results of tests that used the same input, and therefore increases the risk of misleading involved people into making incorrect decisions about what to do next. For example, had I altered a property in the Hazelcast cluster configuration and then observed the altered behavior, I would have likely made a detour by relating that change in output to the property, directing my research efforts into a futile direction and wasting precious time. So, eliminating side effects increases the efficiency with which the results of a test for any “thing” can be compared, understood, and reasoned about, and this, ultimately, safes time and money.
The Value Of Creating Initial State Quickly
Above, we have established, in short, that side effects hurt testability and that they consequently must be avoided as far as possible during test execution. But: What if that “as far as possible” isn’t very far at all and, in fact, can’t be? What if the very nature of your tests entails the creation of side effects, and what if the observable output depends on it?
Thus far, I have used the words “side effects” and “state” very often, even interchangeably. That’s not because they are interchangeable per se, but because they become interchangeable in the context of test execution in all cases where “side effect” means that a piece of state has been created or in some way modified. This is certainly true for testing Hazelcast clusters: Map entries are both state and the side effects of functions that create them.
Here, we arrive at a problem: If you wish to load-test your Hazelcast clusters before rolling out the configuration that spawned them to production (which you should) and if even the simplest load test has to alter the state of the Hazelcast cluster somehow by applying load, then it’s not possible to avoid the side effect – in a sense, the side effect is the test. Therefore, in order to maintain high testability and in order for the test results to be comparable, we need some way to mitigate the effects of the side effects – a way to make sure that each test run not only provides the same input to the Hazelcast cluster, but also runs with the same input as far as the state of that cluster is concerned. In other words, for test results to be comparable and those tests to be repeatable, each test needs to act on the same initial state of the target Hazelcast cluster.
What’s the simplest way to bring about a thing’s initial state? Sure: Build (or rebuild) the thing from scratch. In the context of a Hazelcast cluster running on Kubernetes, this means scaling down the StatefulSet to zero and then scaling back up again – to speed things up, you can manually kill Pods, of course, to prevent them from lingering in the Terminating state for their full grace period. Before I implemented state cleaners in Hazeltest, I frequently restarted the Hazeltest clusters under test, and while this fulfilled the goal of providing the same initial state for each iteration of load level or cluster configuration, it came with the drawback that the speed of those restarts was… “distinctly pedestrian”, let’s say. Sure, there’s always emails to reply to or other useful stuff to do while the cluster members take their time to start, so on paper, the time spent waiting isn’t exactly wasted. However, it seems to me that reality is a bit different: Tasks typically get done a lot quicker if you can really focus on them and get yourself into the flow state – exactly the state destroyed by interruptions and context switches. Moreover, being in the flow state and then achieving a great result simply feels a lot more rewarding than achieving a similar or even the same result after many interruptions and detours, and the feelings of being rewarded (or not) seem to contribute a lot to how most people related to their work. So, decreasing the amount of interruptions correlates with an increase of the efficiency of task execution and the satisfaction we derive from both executing the task as well as the achieved result.
The goal, therefore, with all things under test whose testing relies on side effects, to create that initial, clean state as quickly as possible and, ideally, in an automated fashion. This not only speeds up the testing process and hence increases the amount of iterations you can do on the configuration of the test and/or the target thing in question within a given time span, but also allows you, the tester, to seamlessly jump from one iteration to the next – without losing flow and focus.
Cleaning State With Hazeltest
As of this writing, Hazeltest comes with two kinds of state cleaners, both of which will be introduced below. Both kinds of state cleaners have the same purpose: to erase state in a Hazelcast cluster before a load test is started with the usual runners kicking in an performing their load-generation tasks.
Cleaning State Using Runner-Related Cleaners
Hazeltest currently offers test runners for two kinds of data structures in Hazelcast – maps and queues –, but at the time of this writing, only map runners have the ability to perform pre-run eviction on their target maps, so in the following, we’re going to focus on map runners.
Depending on how a map runner is configured, it will apply a certain kind of load by inserting, reading, and removing elements from a set of maps in the target Hazelcast cluster. For example, take a look at the following configuration of the map load runner:
config:
# ...
mapTests:
load:
# ...
numMaps: 10
appendMapIndexToMapName: true
appendClientIdToMapName: false
evictMapsPriorToRun: true
mapPrefix:
enabled: true
prefix: "ht_"
# ...
There are more bits and pieces to the configuration of the map load runner (and indeed map runners in general), but in this example we only concern ourselves with those related to data structure configuration. With the configuration above, the map load runner will spawn ten maps because numMaps is 10 and appendMapIndexToMapName is true. Meanwhile, appendClientIdToMapName is false, meaning the load runner will not append this Hazeltest instance’s unique ID to the map name (assuming only one Hazeltest instance is running, setting this property to true would not have an effect on the number of maps, but if you had, say, ten instances, then the number of maps created on the Hazelcast cluster those instances access would be increased by a factor of ten). Further, map prefix usage is enabled (mapPrefix.enabled), and the prefix to use for the name of each map is configured to be ht_ (mapPrefix.prefix). So, this load runner will act on the following maps in the target Hazelcast cluster (the middle bit of the name – load in this case – is controlled by the runners themselves and not configurable):
ht_load-0
ht_load-1
# ...
ht_load-9
You probably guesses that the property relevant in the context of erasing state from the target map or maps is evictMapsPriorToRun. It has been set to true in the configuration above, so the runner will evict all maps whose names are a result of the above configuration. That is, there is no need to explicitly tell the runner-related cleaner which maps to evict; it will figure that out by itself and simply evict all the maps the runner is going to access.
Here’s a word of caution, though: To simply tell the runner “make sure all the maps you’re going to use are empty before you start using them” sure is convenient, but that convenience can be dangerous: As you can tell from the map names given as examples above, with appendClientIdToMapName: false, nothing about those names makes them unique to the current Hazeltest instance – even if 10.000 instances were running, they’d all access ht_load-0 through -9 if configured like above. Because the convenience of the runner-related cleaner being on autopilot for figuring out target maps doesn’t force you to think explicitly about the maps you whish to delete, it’s easy to accidentally have the cleaner evict maps in use by other Hazeltest instances, or indeed by entirely different actors. So, please keep that in mind when enabling pre-run eviction on a map runner.
With the theory out of the way, let’s get our hands dirty and take a look at a short example! What we’re going to do is deploy a new Hazelcast cluster, create some state in it using Hazeltest, and then deploy another Hazeltest instance with configuration that will make the map runner’s state cleaner evict the previously created maps before the runner starts its load test agin.
The blog-examples repository provides a sub-folder with Helm charts for deploying a small Hazelcast cluster and a single Hazeltest instance. Assuming you cloned the repository and navigated to the hazeltest/the_cleaners folder, you can install the Hazelcast cluster like so:
helm upgrade --install hazelcastwithmancenter ./hazelcast -n hazelcastplatform --create-namespace
Note: In the Helm chart you just deployed, there is an option available to create an Ingress object for accessing the Hazelcast Management Center, but I disabled it for the sake of this example because to make it work, your Kubernetes cluster would need an Ingress Controller to process the Ingress objects, and you’d need to configure your own host name, and potentially the DNS in your local network. Because accessing the Management Center via kubectl port-forward is almost as convenient for testing purposes, we’re simply going to use that. In case you wish to work with Ingress, though, you can re-enable it by setting the mancenter.reachability.ingress.deploy property to true, but don’t forget to provide the correct host name in the (...).ingress.hostName property and make sure it’s known in your local network.
As soon as at least the Management Center Pod is ready, issue the following command in a separate session (separate so you can leave the process running):
kubectl port-forward -n hazelcastplatform svc/hazelcastimdg-mancenter 8080:web
Now, you should be able to summon the Management Center’s web UI by pointing your browser to localhost:8080. In the Storage tab on the left-hand side, the Maps category should indicate that your Hazelcast cluster currently holds zero maps. Since you just deployed that cluster, that is not particularly surprising.
In the next step, you’re going to deploy Hazeltest with a configuration that disables all features but the map pokedex runner:
config:
chaosMonkeys:
memberKiller:
enabled: false
stateCleaner:
maps:
enabled: false
queues:
enabled: false
queueTests:
tweets:
enabled: false
load:
enabled: false
mapTests:
pokedex:
enabled: true
numMaps: 1
appendMapIndexToMapName: true
appendClientIdToMapName: false
evictMapsPriorToRun: false
mapPrefix:
enabled: true
prefix: "ht_"
load:
enabled: false
You may have noticed the stateCleaner sub element in the above configuration, which refers to the second category of state cleaners introduced in the next section. For this example, both state cleaners available in this category have been disabled.
The pokedex runner has been configured to spawn only one map (because one map is sufficient to make the point in this example), and it will append the map index to the map name, but not the Hazeltest instance’s unique ID. Note also that pre-run eviction has been disabled for now because there are no maps to be evicted just yet.
From within the hazeltest/the_cleaners sub folder, run the following command to deploy Hazeltest:
helm upgrade --install hazeltest ./hazeltest -n hazelcastplatform -f ./hazeltest/values-example-1-1.yaml
Upon checking the Management Center UI again, you should notice there is now one map in the Hazelcast cluster, carrying the name ht_pokedex-0. If you let your single Hazeltest instance run for a couple of minutes, you’ll see roughly the following map usage pattern:
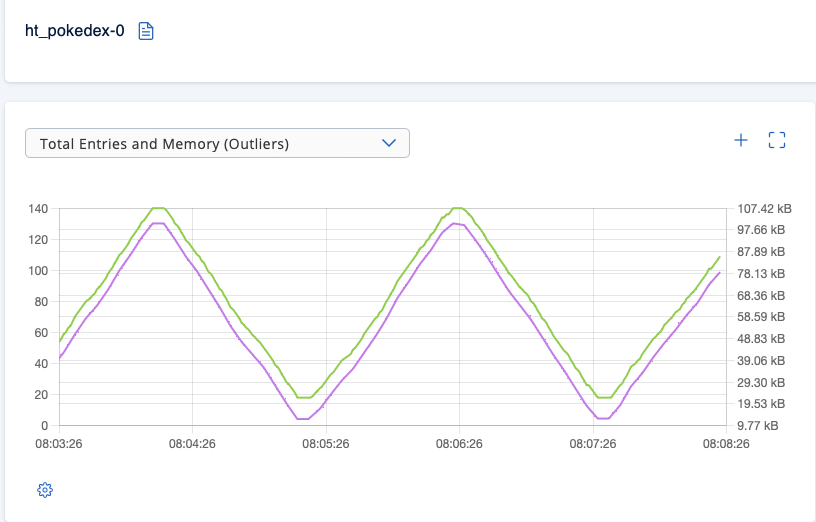
So far, so good. What we want to do next is enable pre-run map eviction. Fortunately, there is another yaml file available for the Hazeltest Helm chart in the hazeltest/the_cleaners sub folder, so all you need to do to replace the running Hazeltest instance with a new one whose map pokedex runner will evict target maps before commencing is run the following command:
helm upgrade --install hazeltest ./hazeltest -n hazelcastplatform -f ./hazeltest/values-example-1-2.yaml
Once the Hazeltest Pod has been replaced, there should be a very obvious dent in the graph showing the ht_pokedex-0 map’s number of entries, similar to what you can see in the following screenshot:
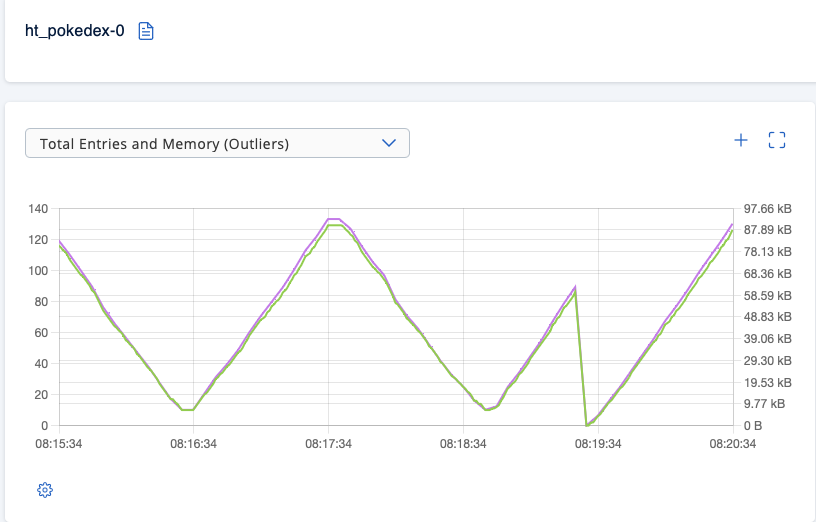
So, thanks to the eviction performed by the map runner, the load test started on a clean state, at least as far as all maps under control by this runner are concerned (we configured it to spawn only one map, but had we configured it to create 100, then it would have evicted 100 maps).
The catch, of course, is that runner-related state cleaners can only evict their own maps, i. e. those maps that they use themselves. That is not a problem in case no actors but Hazeltest are active on a Hazelcast cluster to conduct load tests and in case appendClientIdToMapName has never been set to true for previous Hazeltest instances because the maps in use by the current Hazeltest instance’s runners are the same that previous instances used. However, if there are any maps outside the control of the current Hazeltest instance’s runners – for example, when the map runners of a previous Hazeltest instance were configured to append this instance’s unique ID to the names of the maps they worked with –, the pre-run eviction of the current instance’s runners will not catch those maps, so their state will remain, potentially affecting the results of the load tests the current instance is supposed to run. So, how to catch maps (and queues, even) outside the scope of the current Hazeltest instance?
Cleaning State Using Standalone State Cleaners
Standalone state cleaners have been implemented to offer state cleaning functionality beyond the limitation of runner-related cleaners of being able to only evict state in the data structures they will work with, and they are currently available for maps and queues. If so configured, these cleaners can evict state from all maps and queues in a target Hazelcast cluster, and they will do so before any of the runners is executed, thus ensuring that the configured data structures have been purged of their state before a load test commences.
The configuration of standalone state cleaners is straightforward:
stateCleaner:
maps:
enabled: true
prefix:
enabled: true
prefix: "ht_"
queues:
enabled: true
prefix:
enabled: true
prefix: "ht_"
The above configuration is Hazeltest’s default (at the time of this writing), so if you don’t overwrite these settings, then this is how the state cleaners will be configured. This configuration reflects that state cleaners are currently available for maps and queues (support for other Hazelcast data structures might be added in the future), and that each cleaner can be individually enabled or disabled. Optionally, a prefix can be configured for the state cleaner to use as a filter when evaluating which maps or queues to evict. So, in the above example, both the map and queue state cleaner will consider maps or queues whose name starts with ht_.
If you disable prefix usage, then the state cleaner will consider all data structures corresponding to its type (maps or queues) for eviction, except the data structures internal to Hazelcast, which the system keeps around for its own housekeeping, such as the __sql.catalog map. While these data structure contain state, too, and therefore could possibly act as “hidden input” to a load test with the potential of altering its output, evicting these data structures might have unexpected side effects on the entire cluster, potentially entailing an even more impactful effect on the execution of a load test. Therefore, it is much safer to leave these internal data structures as they are, and evict only those non-internal data structures that other Hazeltest instances, or indeed other actors entirely, have previously used.
Let’s get our hands dirty once again by conducting a small example, in which we’ll make use of the standalone state cleaner for maps. First, we’re going to deploy a fresh Hazelcast cluster and use Hazeltest to create some state in it, but this time, we’re going to use maps for Hazeltest that carry this instance’s unique ID in their name. In this way, map runners of ensuing instances won’t be able to use those maps – and neither will their state cleaners. This is a deliberate design choice in Hazeltest: There must be a possibility for users to configure that individual Hazeltest instances must only work on their own maps. So, to evict the state present in maps that carry the unique ID of a previous Hazeltest instance in their name, we need standalone state cleaners, and we’re going to deploy them after the first Hazeltest instance has created some state in the cluster. Also, to get a more top-down view of the effects of both the load creation and the state cleaning on the Hazelcast cluster, we’re going to make use of a Helm chart for rolling out Prometheus that has been added to the blog-examples repository for the sake of this example.
First, we’re going to deploy a small Hazelcast cluster along with the Hazelcast Management Center. Assuming again you cloned the blog-examples repository and have a terminal session open within the hazeltest/the_cleaners sub folder, you can do so by running the following command:
helm upgrade --install hazelcastwithmancenter ./hazelcast -n hazelcastplatform --create-namespace
Once at least the Management Center Pod is up, establish a port forwarding to its UI once again in a separate session like so:
kubectl port-forward -n hazelcastplatform svc/hazelcastimdg-mancenter 8080:web
There won’t be anything new and exciting here just yet; the Management Center will inform you that there are two members (if you installed the Helm chart without modifications) and that no data structures are present. Before you’re going to change that, however, let’s roll out Prometheus:
helm upgrade --install prometheus ./prometheus -n monitoring --create-namespace
As a last preparation step before creating some load on the Hazelcast cluster, you’ll want to set up a port forwarding to Prometheus’ web UI once the Prometheus Pod is ready (the Prometheus chart comes with the option for deploying Ingress, too, but once again, that would require an Ingress Controller in your Kubernetes cluster and you’d have to specify a valid host name in the chart’s values.yaml file as well as potentially tinker with your local DNS, so for the sake of simplicity, we’re just going to use the good ol’ port forwarding here):
kubectl port-forward -n monitoring svc/prometheus 9090:web
Summon Prometheus’ web UI (available on localhost:9090 if you followed the port-forwarding suggestion rather than working with Ingress) and give the following query a go, which will retrieve the number of map entries owned per member and map (note that we’re excluding Hazelcast’s own internal maps from being considered):
com_hazelcast_Metrics_ownedEntryCount{tag0!~"\"name=__.*\""}
This will return an empty result, which confirms that our little Hazelcast cluster must be pretty bored right now. So, let’s change that by deploying Hazeltest using yet another example values.yaml file provided in the blog-examples repository:
helm upgrade --install hazeltest ./hazeltest -n hazelcastplatform -f ./hazeltest/values-example-2-1.yaml
While this instances starts going about its business on our Hazelcast cluster, let’s take a short look at an excerpt from the values-example-2-1.yaml file. There is more to this file than what’s shown here, but the excerpt contains the pieces of configuration important for understanding what you’ll see unfold in the target Hazelcast cluster:
config:
# ...
mapTests:
pokedex:
enabled: true
numMaps: 100
appendMapIndexToMapName: true
appendClientIdToMapName: true
evictMapsPriorToRun: false
# ...
What this will do is deploy a Hazeltest instance configured with a map pokedex runner that will spawn 100 maps, and because appendClientIdToMapName is true, this Hazeltest instance will append its unique ID to the name of each map. Also, pre-run eviction has been disabled.
Before heading over to Prometheus, let’s give the Management Center’s UI a short visit to check on the map names. What you see once you headed to the Maps section in yours should roughly correspond to the following:
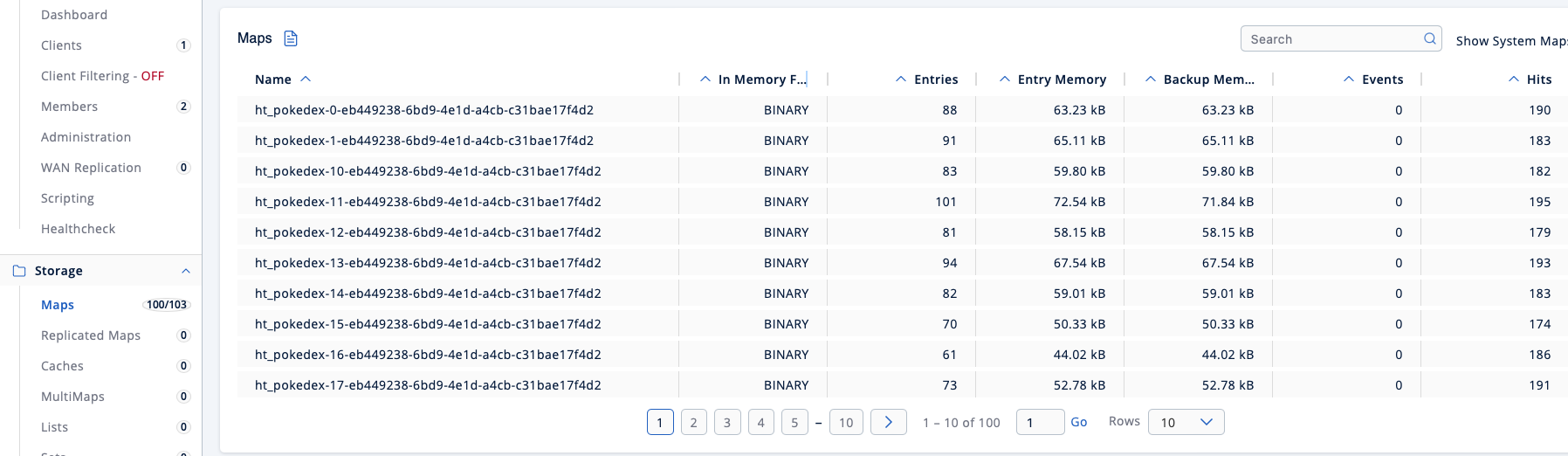
So, there are now 103 maps in the cluster – three system-internal, 100 created by our Hazeltest instance’s map pokedex runner –, and each map name carries this Hazeltest instance’s unique ID. It therefore makes sense that runner-related cleaners on an ensuing instance would not be able to access those maps, unless coincidence would have it to give this instance the same ID than the previous one (if that happens to you, please make sure to buy a lottery ticket right away, because winning the lottery is more likely than any sane UUID generator producing the same UUID twice).
Our small detour via the Management Center provided the map pokedex runner with enough time to create load in the Hazelcast cluster, so head over to Prometheus’ web UI again and re-run the above query. This time, the result list will contain quite a few entries, so let’s compact the list by summing the number of owned map entries by map name:
sum by (tag0)(com_hazelcast_Metrics_ownedEntryCount{tag0!~"\"name=__.*\""})
The Graph tab will present you with an image similar to the following:
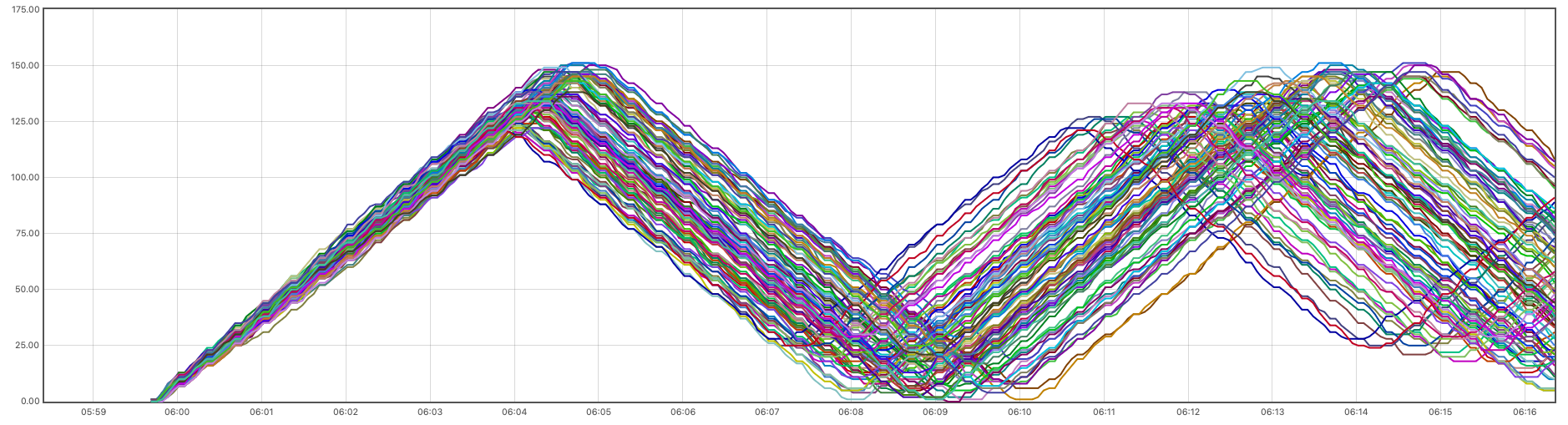
Looking at this, it probably won’t hit you as a surprise if I told you that the default test loop type on all map runners is the boundary test loop – called so because, well, it inserts and deletes entries such that the number of entries in each target map remains within a certain boundary (evaluated individually and, by default, with a bit of randomness for each of the numMaps (here: 100) goroutines working on maps, so the boundaries, by default, will not be the same for every map). Upon closer inspection, you’ll also notice that the lines overlap at first, but then start diverging quickly. That’s because the boundary test loop for each of the 100 specified maps is configured with random sleeps in order to increase the realism of the created load (if you think of 100 real-world clients, it would be unrealistic to assume they’d all insert and delete entries to and from their respective maps at exactly the same pace).
Next, we’re going to examine the effects of the standalone map cleaner on the target Hazelcast cluster. In yet another values file for Hazeltest, values-example-2-2.yaml, configuration for standalone state cleaners has been removed, so the default values will be applied. Again, these are (for the standalone map cleaner):
stateCleaner:
maps:
enabled: true
prefix:
enabled: true
prefix: "ht_"
# ...
This looks suspiciously like it could match the 100 maps created by the map pokedex runner of the still-running Hazeltest instance. So, replace the latter by running the following command:
helm upgrade --install hazeltest ./hazeltest -n hazelcastplatform -f ./hazeltest/values-example-2-2.yaml
This will spawn a new Hazeltest instance in place of the existing one. After letting it run for a couple of minutes and then go check out Prometheus once again to re-run the previous query, you should see an image roughly resembling the following (in my case, the lines indicating the sum of owned entries per map under control by the first Hazeltest instance had diverged quite a bit when I snapped this screenshot because all the previous text was written between taking the first and the second Prometheus screenshot, so they’ll probably be less divergent in your case):
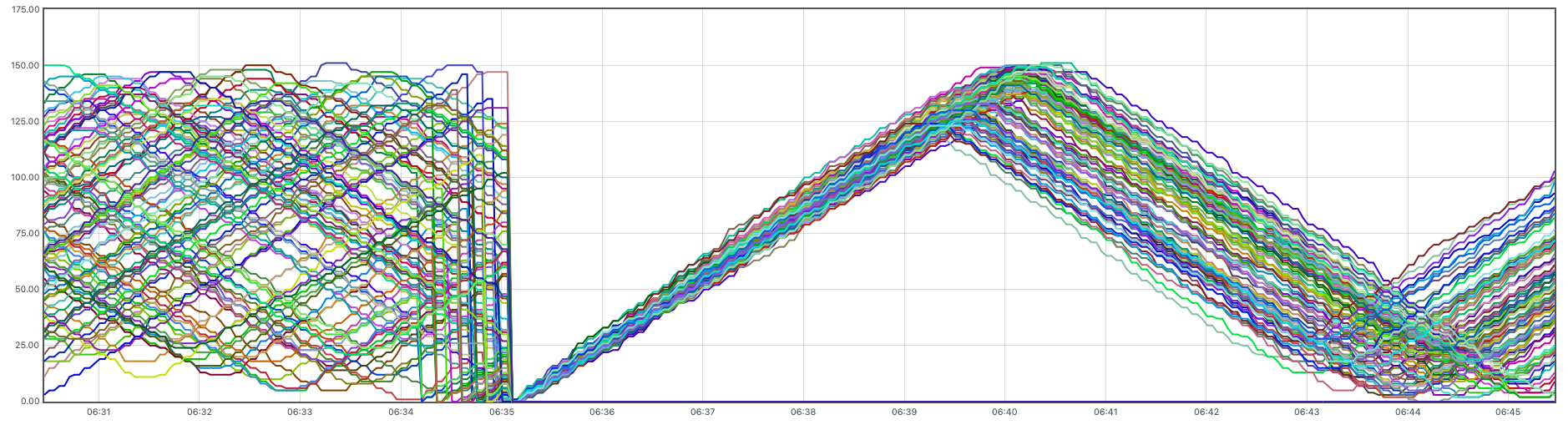
This image indicates that all maps present in the cluster were evicted by the standalone map cleaner of the new Hazeltest instance before this instance’s map pokedex runner started. Therefore, previous state (in terms of maps, in this example) cannot alter the output of the current load test by acting as “hidden input” uncontrollable by means of load test configuration.
After having established the standalone map cleaner does what it’s supposed to do (and, by extension, the standalone queue cleaner, although we haven’t tested it here, so you’re just going to have to take my word for it), there might be two open questions dangling in your mind:
- Okay, but what about the existing maps? Have they been evicted or outright deleted from the cluster?
- I’m forced to think about which maps and queues to clean with the standalone state cleaner (as opposed to the runner-related cleaners, which will figure it out themselves), hence it’s unlikely I’m going to accidentally clean maps or queues I didn’t want cleaned. Still, is there some way to verify which maps or queues my standalone state cleaners hit? After all, the potential of accidentally wiping out way more than intended is there…
And these are very good questions! Let’s start by answering the first one. Head over to your Management Center UI once more and check the list of maps. You should see something similar to the following:
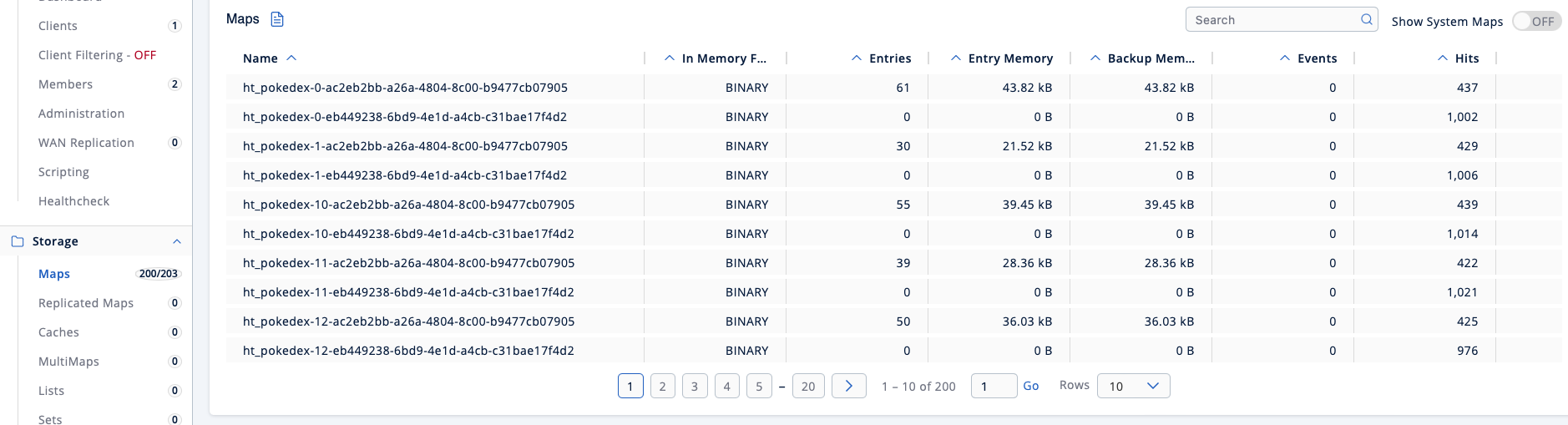
So, there are now 203 maps in total, and if the three system-internal once are subtracted, it’s easy to figure out the 100 maps created by the previous Hazeltest instance are still around – they are empty, so they won’t occupy any memory and the cluster doesn’t have to do anything with them anymore, but they still exist as empty “shells”. Thus, standalone state cleaners currently don’t delete their target data structures, but only evict them (though the option for deletion might be added in the next iteration of this feature).
Onward to the second question, which was, in short, whether there is a way to check which maps or queues a standalone state cleaner has hit. And indeed, there is! If you previously deployed the Hazeltest Helm chart without modifications, then there will be a Service object in front of the Hazeltest Pod that can be used to conveniently access the latter from your local machine. At this time, the other port forwardings that might still be running on your machine are not required anymore, so you can terminate them and re-use one of the sessions to establish a port forwarding to the aforementioned Hazeltest Service:
kubectl port-forward -n hazelcastplatform svc/hazeltest 8080:http
(Port 8080 was previously occupied by the Management Center port forwarding, so if that’s still running, you’ll need to specify another port.)
The information we’re looking for is retrievable via the application’s status endpoint, :8080/status, which you can reach, thanks to the port forwarding just established, on your local machine. To retrieve and format the application’s current status info, run the following command:
curl localhost:8080/status | jq
The output will contain more than the following, but the standalone state cleaner’s status is what we’re looking for. On your end, it should roughly resemble the following (albeit more elaborate, because the following was truncated):
{
...
"stateCleaners": {
"mapCleaner": {
"finished": true,
"ht_pokedex-0-eb449238-6bd9-4e1d-a4cb-c31bae17f4d2": 4,
"ht_pokedex-1-eb449238-6bd9-4e1d-a4cb-c31bae17f4d2": 8,
"ht_pokedex-10-eb449238-6bd9-4e1d-a4cb-c31bae17f4d2": 15,
...
"ht_pokedex-98-eb449238-6bd9-4e1d-a4cb-c31bae17f4d2": 9
},
...
}
}
Unsurprisingly, the map cleaner reports that it’s finished. The ensuing list contains the names of all maps whose state it has evicted, along with the number of entries that were evicted. So, to verify the standalone map cleaner (and the standalone queue cleaner, for that matter) only hit the data structures you expected and thus make sure that you configured it correctly, you can always consult Hazeltest’s status endpoint.
Wrap-Up: What State Cleaners Can Do For You
We kicked off this blog post by giving the Haskell programming language a short visit, which is a purely functional language – a program written in Haskell does not possess any internal state because running the program’s pure functions will never have any side effects on the program itself, no matter how hard you try. A direct result of this is that Haskell programs tend to have a very high degree of testability – if a unit under test behaves like a function in the mathematical sense (same input will always yield the same output), then writing a thorough test for it will be pretty straightforward. As it turns out, then, state as the result or indeed the embodiment of side effects hurts testability – if the state acts as a “hidden input” to test execution (hidden in the sense that it is not under control by the test itself), it may alter the output, thus rendering the results virtually incomparable with the results of previous tests. This has profound ramifications due to the the importance of test results comparability as a core aspect of testability: For the effects of changes in the “thing” under test – whatever that thing might be – to be measurable, before vs. after comparisons are indispensable, and if the observable output depends on more than this change, then the effects of the change can never be reliably gauged, thus making the thing under test very hard to understand and reason about. Therefore, the absence of “hidden input” to test execution is crucial for facilitating a high level of testability.
The challenge with testing Hazelcast clusters is that state as the result of test execution is inevitable – to make sure, say, your map configuration works the way you want it to work, you’ll have to put some values in the map and read them back, so the load test tool has to create state as a side effect in the Hazelcast cluster. As was demonstrated in this blog post by means of a small example, this state might well act as just the dreaded hidden input we’re trying to avoid. So, if the side effect of state is a necessary byproduct of test execution, then at least we must ensure that this state will never act as input to a later test. The only way to achieve this is to wipe the state of a previous load test, and this is where Hazeltest’s state cleaners can help you a great deal: Instead of having to redeploy your Hazelcast cluster over and over again to create the same baseline for every test, the state cleaners let you evict data structures containing state before the runners start with their load test tasks.
There are two types of state cleaners in Hazeltest; runner-related cleaners, and standalone cleaners. The former are currently only available for maps, and they have the drawback that they can only evict maps the current Hazeltest instance has access to. For example, if a previous Hazeltest instance’s map runners attached this instance’s unique ID to the names of the maps they created in Hazelcast, then map runners of ensuing instances will never be able to work with those maps, hence their cleaners won’t, either. On the plus side, though, runner-related cleaners are very easy to configure: Simply set evictMapsPriorToRun (or evictQueuesPriorToRun, once the cleaning functionality has been implemented for queue runners, too) to true and the cleaner will figure out the target maps (or queues) by itself. Standalone state cleaners (currently available for both maps and queues), on the other hand, can work with all maps and queues in the target Hazelcast cluster and, if so configured, will wipe them clean of all state before any runner starts. This ensures that the baseline of state in the target Hazelcast cluster is always the same for each test iteration.
Because state cleaners (no matter the kind) can create the initial state for a load test very quickly and conveniently, they help achieving the goal of efficiently maintaining test results comparability, and facilitate higher testing velocity by enabling you to do more test iterations within a given unit of time. But the idea of state cleaners goes beyond merely their impact on the testability of a Hazelcast cluster – being able to start one load test right after the previous one has ended means that you can stay focused on the task of load-testing the cluster, without the casual interruptions of having to redeploy it (or otherwise making sure the Hazelcast members don’t carry the state of previous load test iterations before the next iteration starts). Therefore, you can remain in that precious flow state – the state in which you’re so focused on a task that everything else becomes a blur and you even forget to get fresh coffee –, increasing your efficiency and effectiveness and, probably, also your levels of satisfaction with your work because you didn’t have to diffuse your precious focus over and over again while the Hazelcast cluster was restarting and you wanted to use the in-between time for doing other things (such as responding to new email – classic).
For the next iteration of the state cleaner feature, I would like to add state cleaning functionality to queue runners, and implement the option for standalone runners to completely delete their target data structures rather than merely evict them. So, stay tuned for more news!
