Workload Reachability 3: Ingress

One entry point to reach them all, one consolidated set of rules to find them, one Service exposed to bring them all, and in the cluster distribute them; in the Land of Kubernetes where the workloads lie.
In the upcoming sections, you’ll get introduced to the concept of Ingress – as you might have guessed from the slightly re-interpreted version of the infamous One ring to rule them all Lord of the Rings quote in this blog post’s description, Ingress is a means to expose many workloads using only a single exposed Service. This will be an interesting journey, so get a fresh mug of coffee and buckle up!
- The Challenge
- Behold: Ingress
- Examining Ingress
- Ingress In Action
- Ingress And Namespace Isolation
- Cleaning Up
- Summary
The Challenge
The previous blog post covered the various Service types, and for the three most common Service types – ClusterIP, NodePort, and LoadBalancer –, specific attention was put on how appropriate each type of Service is for exposing cluster-internal workloads to the external world. In doing so, we’ve seen that even the most promising contender for this challenge, the LoadBalancer Service type, is not ideal – while very simple to use (given the cloud provider has done some configuration work behind the curtains), exposing many workloads employing this Service type would require many such Services, and since cloud providers typically charge for each of them, the fun would end as soon as the first bill comes in. Plus, exposing so many Services to the external world seems unelegant in a conceptual way, too – wouldn’t it be a lot nicer to expose only a single entrypoint that then distributes incoming requests to the cluster-internal workloads based on a set of rules?
Indeed, it would, and, of course, Kubernetes has a solution in store for that. Meet the Ingress resource!
Behold: Ingress
The idea behind Ingress is that it should act as a single, central entry point into the cluster that accepts incoming requests and funnels them to cluster-internal workloads based on a declarative set of rules. The component acting on those rules – the Ingress Controller – is usually a Deployment within the cluster itself that gets exposed outside the cluster using a LoadBalancer Service, but because it can inspect incoming requests to figure out their targets, match this with the given set of rules, and based on that make informed forwarding decisions, the Ingress Controller can be the only LoadBalancer Service a whole range of cluster-internal workloads can be reached through.
Ingress Spec Versus Ingress Controller
You might have noticed there were two terms in the preceding section with regards to the idea of a single cluster entrypoint – Ingress and Ingress Controller –, and indeed, while the idea is simple in theory, its realization entails a high level of complexity, and one way this complexity shows in Kubernetes is that the concept of “Ingress” is split into two components:
- The Ingress resource specification itself. This is the usual plain-text declarative description of desired state you know from other native Kubernetes resources (Pods, Services, etc.), where, in case of Ingress, “desired state” is the set of routing rules and all corresponding configuration. But if you simply committed such a resource to the Kubernetes API server, you’d find that nothing happens, which is because, by default, there is nothing in a Kubernetes cluster to act on that resource spec.
- An Ingress Controller. Out-of-the-box, Kubernetes ships with many controllers that contribute to the overall cluster state by managing their specific area of responsibility in scope of their control loops (Deployment Controller, Endpoints Controller, Node Controller, …), but an Ingress Controller is not among them. This is because the Ingress Controller as the component acting on Ingress specifications can express itself as either a load balancer or a reverse proxy (or both!) depending on its configuration, and each of these topics is so vast and diverse with so many use cases to fulfil that there is no single Ingress Controller that can be used universally. Therefore, the Kubernetes team have made the Ingress Controller pluggable and left the decision which one to use to the cluster administrators.
Before we take a look at an Ingress spec, let’s talk shortly about which use cases Ingress is a good fit for as well as the use cases it can’t be applied in.
What Use Cases To Use Ingress For
If you have many workloads running in your cluster exposing HTTP-based APIs that need to be publicly accessible, you’ll find Ingress very helpful as it eliminates the need for a high number of LoadBalancer Services. The important keyword here is HTTP-based – in order to fulfil its routing tasks, the Ingress Controller has to work on layer 7 of the OSI reference model (the application layer), limiting the kind of traffic it can process to HTTP and HTTPS (some Ingress Controllers like Nginx and Traefik v2 are advertised as being able to deal with TCP and UDP traffic, too, but this area is still under active development and the way those capabilities are configured will likely be specific to the specific Ingress Controller used). This means if a workload cannot handle HTTP-based traffic, Ingress is not an option for exposing it outside the cluster.
To expose workloads not offering HTTP-based APIs, NodePort or LoadBalancer Services are the go-to solution because their underlying mechanisms operate on OSI layer 4, the transport layer – they don’t examine package content and therefore only have access to very simple load balancing algorithms like random and round robin, but the upside of this is that Services can deal with TCP, UDP, and (since Kubernetes v1.20) SCTP traffic. (One might point out the reduced computing overhead of layer 4 load balancing compared to layer 7 load balancing as an additional benefit, but today’s hardware is so powerful this benefit will probably be negligible or outright irrelevant in most cases.)
To drive home the point, here’s an example: One of my clients runs a popular in-memory data grid platform on their on-premise Kubernetes clusters. The platform is made up of two distinct applications: the grid itself, which forms a cluster of members in the form of many Pods in the Kubernetes cluster, and an accompanying management center, which offers a browser-based UI to explore cluster state. We exposed the management center via a Ingress, but the grid members only offer an API using a special TCP-based protocol, and thus had to be exposed by means of a LoadBalancer Service.
Examining Ingress
In the upcoming sections, you’ll get introduced to a simple Ingress specification. As always, a manifests file awaits you over on my GitHub, and if you examined it, you’d find that there is a bit more than only an Ingress specification. That’s because to be able to play around with it a bit later on, we need some workloads in the form of a bunch of Pods as well as a couple of Services that we can use as the backends for the Ingress spec. I’m going to explain this example scenario first before we get into the ins and outs of the Ingress spec.
Example Scenario
Let’s imagine a team of developers work on a platform for managing images, and they’ve come up with three microservices: the image labeling service labels images, the image text extraction service extracts an image’s text using OCR, and the image search service, well, searches images. Thus far, to deploy those microservices to Kubernetes, they have written three Deployment specs and three ClusterIP Services plus a namespace to very handily wrap it all in one logical realm. They’ve called the namespace imagemanager, and the Service names are image-labeling, image-text-extraction, and image-search, respectively. The next thing the developers would like to do is expose the Service objects outside the cluster, and they’ve decided the best and most elegant way to accomplish this would be to employ Ingress.
The Ingress Spec
With the sample scenario laid out, let’s take a look at the Ingress the team will use to expose their Services:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: imagemanager-services
namespace: imagemanager
annotations:
traefik.ingress.kubernetes.io/router.entrypoints: web, websecure
spec:
rules:
- host: api.imagemanager.io
http:
paths:
- path: /labeling
pathType: Prefix
backend:
service:
name: image-labeling
port:
name: http
- path: /search
pathType: Prefix
backend:
service:
name: image-search
port:
name: http
- path: /text-extraction
pathType: Prefix
backend:
service:
name: image-text-extraction
port:
name: http
The first thing you may notice is the annotation – it doesn’t very much make the impression of being generally applicable to Ingress specs, and indeed, this annotation is specific to the Traefik load balancer/reverse proxy that we will use as our Ingress Controller later on (annotations are a frequently used means on Ingress resources to configure options related to specific Ingress Controllers). For now, let’s take a look at how to assemble a rule to route HTTP(S) traffic.
Remember all the talk in the paragraphs above about the set of rules the Ingress Controller will use to make its routing decisions? Well, the spec.rules field is the place to specify them, and it is the Ingress Controller’s job to make sense of whatever you specify under this property. As you can see from the Yaml above, the spec.rules field is a list of objects, and each rule comprises the following information:
- A host name (
spec.rules.host). This property is optional, and if not specified, the Ingress is reachable under whatever external IP theLoadBalancerService of the Ingress Controller has been assigned by the system. If specified, the host name has to be the fully qualified domain name of a network host according to RFC 3986 with the following exceptions:- IPs are not allowed
- It is invalid to specify ports, so colons will be ignored
- More an extension rather than an exception, an Ingress rule’s host name can contain an asterisk to define a wildcard
- A list of paths. This is where things get really exciting for our imaginary team of developers because the list of paths allows them to associate a set of paths with a set of backends. In the example scenario outlined in scope of the previous section, there are three Services, and the developers have defined three descriptive paths, each of them pointing to a corresponding backend. For the Ingress Controller to route a request to a specific backend, both the host and the path must match the contents of the request’s headers.
- Finally, the backend, which defines the Service object the request should be routed to if its headers match both the rule’s host and path. As you can see in the example above, in addition to the Service name, the name of the port (or, alternatively, the port number by means of the
port.numberproperty) has to be specified, too.
Additionally, path-based routing decisions can be fine-tuned by means of the pathType property. In the Yaml above, the path type was set to Prefix in all cases, which means rule path and request path are compared in terms of the tokens derived by splitting both by the forward slash. For example, request paths /search and /search/text would both match the /search rule path, but not /search-text or /text/search. You can find more examples on the behavior of the two different path types in the official Kubernetes docs.
Other options for the pathType property are available in the form of the Exact path type, which matches paths exactly, and the ImplementationSpecific path type, which delegates the path matching to the Ingress Controller.
Ingress In Action
After all this theory, you probably can’t wait to get your hands dirty, and in the upcoming sections, you’ll do just that. We’ll start by providing you with a small, single-host Kubernetes cluster you can use to play around.
Preparation Work
To complete the following section, you’ll need two tools on your machine: kubectl and helm.
Installing K3s
After completing this section, you’ll have a fresh, k3s-based, single-host Kubernetes cluster up and running on your Linux machine (in case you already have a Kubernetes cluster at your disposal, feel free to jump ahead). I’ve mentioned k3s elsewhere, and in my opinion it’s a fantastic way to get started with using Kubernetes as the requirements to install and run it are very basic – if you have a server or really just a laptop running a modern Linux distribution, you should be good to go.
The k3s team offer a convenient installation script you could run as-is, but that’s not exactly what we want in this case – by default, k3s comes with Traefik v1 as its Ingress Controller, but in the context of this blog post, Traefik v2 is the more suitable option (for example, it comes with a very handy dashboard that we’re going to explore a bit later on). Therefore, to disable the default Traefik installation, run the script as follows:
$ curl -sfL https://get.k3s.io | sh -s - --disable=traefik
Or, in case you have already downloaded the script:
$ INSTALL_K3S_EXEC="--disable=traefik" whatever-you-named-the-script.sh
Once the installation script has executed, you can verify installation success by viewing the available nodes and checking Pod health, which you could achieve by using the kubectl executable contained in the k3s installation (which is really just a link to an executable called k3s, but it gets the job done), but it’s much more convenient to store the cluster details – available at /etc/rancher/k3s/k3s.yaml – in your Kubeconfig file and then use your machine’s kubectl executable, so simply (sudo) cat the contents and put them into your Kubeconfig, which is usually ~/.kube/config (pay attention, though, if you use a VM or a remote machine – in this case, you’ll have to replace the 127.0.0.1 IP given for the server with whatever IP your VM or remote machine is reachable under).
Once you’ve done that, you can proceed with checking the health of your freshly installed k3s cluster using the following commands:
# Because why not
$ alias k=kubectl
# Check available nodes -- single-node cluster, so will yield only one entry
$ k get node
NAME STATUS ROLES AGE VERSION
parallels-parallels-virtual-platform Ready control-plane,master 93s v1.22.5+k3s1
# Verify all Pods are running nicely (we expect three Pods in total on a fresh install without Traefik)
$ k get po -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-85cb69466-2jx2c 1/1 Running 0 51s
kube-system metrics-server-9cf544f65-cx762 1/1 Running 0 45s
kube-system local-path-provisioner-64ffb68fd-fxhmk 1/1 Running 0 38s
Deploying Traefik v2
As mentioned previously, we’re going to use Treafik v2 as the Ingress Controller of our choice. Installing it with using Helm is very simple:
# Add the Traefik Helm repo
$ helm repo add traefik https://helm.traefik.io/traefik
# Update chart information
$ helm repo update
# Install Traefik
$ helm install traefik traefik/traefik
NAME: traefik
LAST DEPLOYED: Thu Feb 3 22:24:07 2022
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
If the output of your install command looks akin to the above, you can proceed to checking whether the Traefik Pods have started:
# '-n default' could also be omitted here, only specified for sake of completeness
$ k -n default get po
NAME READY STATUS RESTARTS AGE
svclb-traefik-rtk2f 2/2 Running 0 118s
traefik-7c48dbf949-zl47f 1/1 Running 0 118s
Traefik is running nicely, and before we move on, let’s examine two interesting details. Remember I mentioned the Ingress Controller is itself one or multiple Pods in the cluster, usually controlled by a Deployment object, and that the Controller is exposed outside the cluster via a LoadBalancer Service? Well, let’s see this in action:
$ k get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
traefik 1/1 1 1 9m15s
$ k get svc --selector="app.kubernetes.io/name=traefik"
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
traefik LoadBalancer 10.43.245.102 10.211.55.6 80:30317/TCP,443:30966/TCP 11m
It seems obvious the LoadBalancer Service must refer to the Traefik Pod, but let’s double-check:
# View Traefik Pod along with IP address and its labels (truncated here)
$ k get po --selector="app.kubernetes.io/name=traefik" -o custom-columns=NAME:.metadata.name,IP:.status.podIP
NAME IP
traefik-7c48dbf949-zl47f 10.42.0.117
# Get description of 'traefik' Service, focus on selector and endpoints list (other lines omitted)
$ k describe svc traefik
...
Selector: app.kubernetes.io/instance=traefik,app.kubernetes.io/name=traefik
...
NodePort: web 30317/TCP
Endpoints: 10.42.0.117:8000
...
NodePort: websecure 30966/TCP
Endpoints: 10.42.0.117:8443
So indeed, the Ingress Controller has been rolled out as a single Pod governed by a Deployment object, and there is a LoadBalancer Service exposing the Controller on two ports – one for plain HTTP, another for HTTPS communication. This seems to make a lot of sense – the Ingress Controller is supposed to act as a single entry point into the cluster and, as such, make routing and forwarding decisions about incoming requests, and the LoadBalancer Service helps with this as it forwards all traffic to the Controller, which can then distribute it in the cluster.
Modifying The /etc/hosts File
The sample Ingress specs you’re about to deploy to your cluster work with host names, and to be able to make requests against those host names from outside the cluster and get the expected results, it’s necessary to tell your workstation about the DNS mapping between the Ingress Controller’s external IP and those host names. For your convenience, here’s a command to retrieve the external IP:
$ k get svc traefik -o custom-columns=EXTERNAL_IP:.status.loadBalancer.ingress[0].ip
EXTERNAL_IP
10.211.55.6
So, in my case, the external IP is 10.211.55.6, hence I have the following two lines in my /etc/hosts file:
10.211.55.6 api.imagemanager.io
10.211.55.6 api.notesmanager.io
We’re going to check whether the DNS works correctly later on once we’ve added the Ingress resources to the cluster.
Using Ingress
Finally, with all the preparation work out of the way, we can make use of the freshly installed k3s cluster and the Traefik v2 Ingress Controller. We’re going to apply the first out of three sample manifests next, which will create the objects I’ve previously mentioned in the Example Scenario paragraph:
$ k apply -f https://raw.githubusercontent.com/AntsInMyEy3sJohnson/blog-examples/master/kubernetes/workload-reachability/deployments-with-ingress-1-imagemanager.yaml
namespace/imagemanager created
deployment.apps/image-labeling created
deployment.apps/image-text-extraction created
deployment.apps/image-search created
service/image-labeling created
service/image-search created
service/image-text-extraction created
ingress.networking.k8s.io/imagemanager-services created
In particular, the Ingress spec handed to the API server here is the one you’ve seen previously in section The Ingress Spec.
Wait a couple of moments until all the Pods have come up:
$ watch kubectl -n imagemanager get pod
Every 2.0s: kubectl -n imagemanager get pod
NAME READY STATUS RESTARTS AGE
image-text-extraction-85f69c4d7d-5qnqz 1/1 Running 0 71s
image-text-extraction-85f69c4d7d-cdfrp 1/1 Running 0 71s
image-labeling-7ccc6f56ff-rhbnt 1/1 Running 0 71s
image-labeling-7ccc6f56ff-fhbcg 1/1 Running 0 71s
image-text-extraction-85f69c4d7d-xr2wf 1/1 Running 0 71s
image-search-657d87994f-9xcgf 1/1 Running 0 71s
image-labeling-7ccc6f56ff-txzmp 1/1 Running 0 71s
image-search-657d87994f-7wbjg 1/1 Running 0 71s
image-search-657d87994f-nrnr2 1/1 Running 0 71s
Examining The Traefik Dashboard
Traefik v2 exposes a nice dashboard on port 9000 of the traefik Pod, but it’s only reachable externally via the port-forward command, which you can run in a terminal as follows:
$ k port-forward -n default "$(k -n default get po --selector="app.kubernetes.io/name=traefik" -o custom-columns=NAME:.metadata.name --no-headers)" 9000:9000
Forwarding from 127.0.0.1:9000 -> 9000
Forwarding from [::1]:9000 -> 9000
Now, you’ll be able to bring up the dashboard on localhost:9000/dashboard/ (mind the trailing slash!), which should look akin to the following:
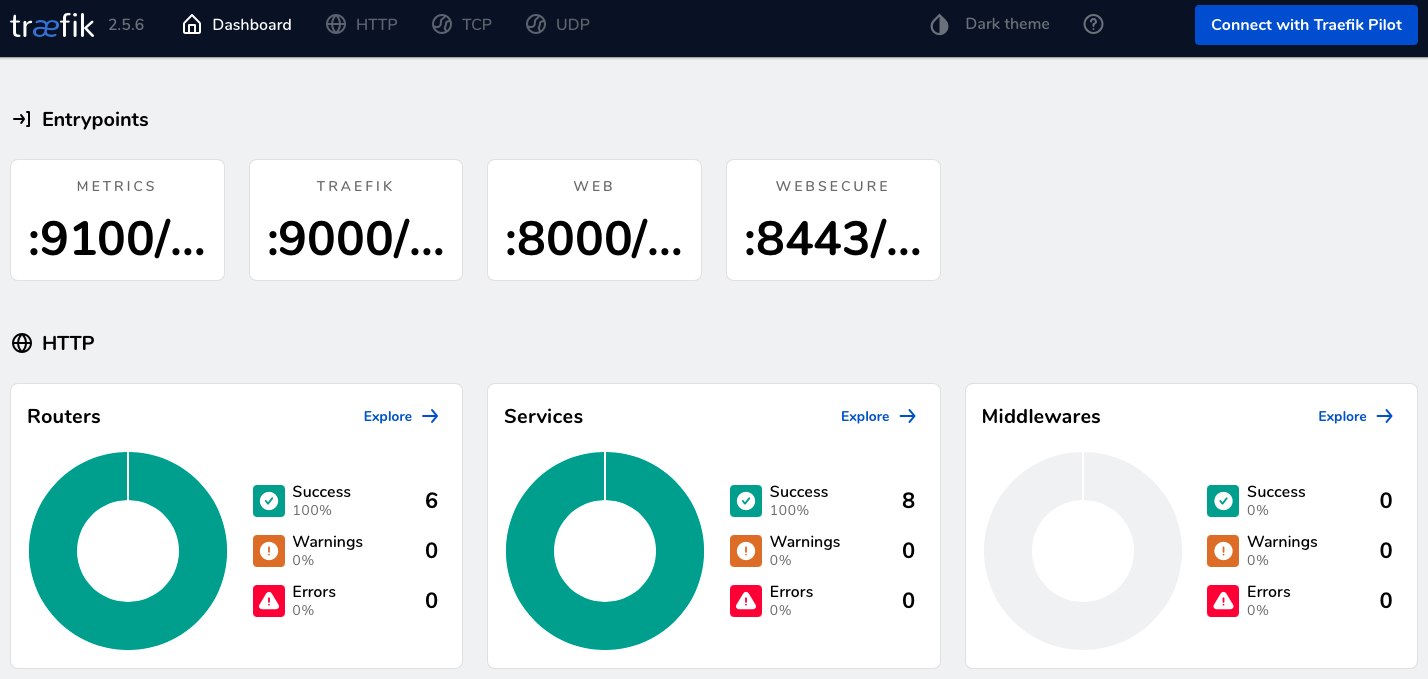
In there, let’s first examine the Routers section. A Router is a Traefik-specific concept that binds routing rules to their corresponding backend Services, so we can check whether the routing rules specified in the Ingress resource have been interpreted correctly (recall the development team have implemented three microservices, image-labeling, image-text-extraction, and image-search, and that there are three path-based routing rules supposed to forward traffic to them, namely, on the paths /labeling, /text-extraction, and /search, respectively):
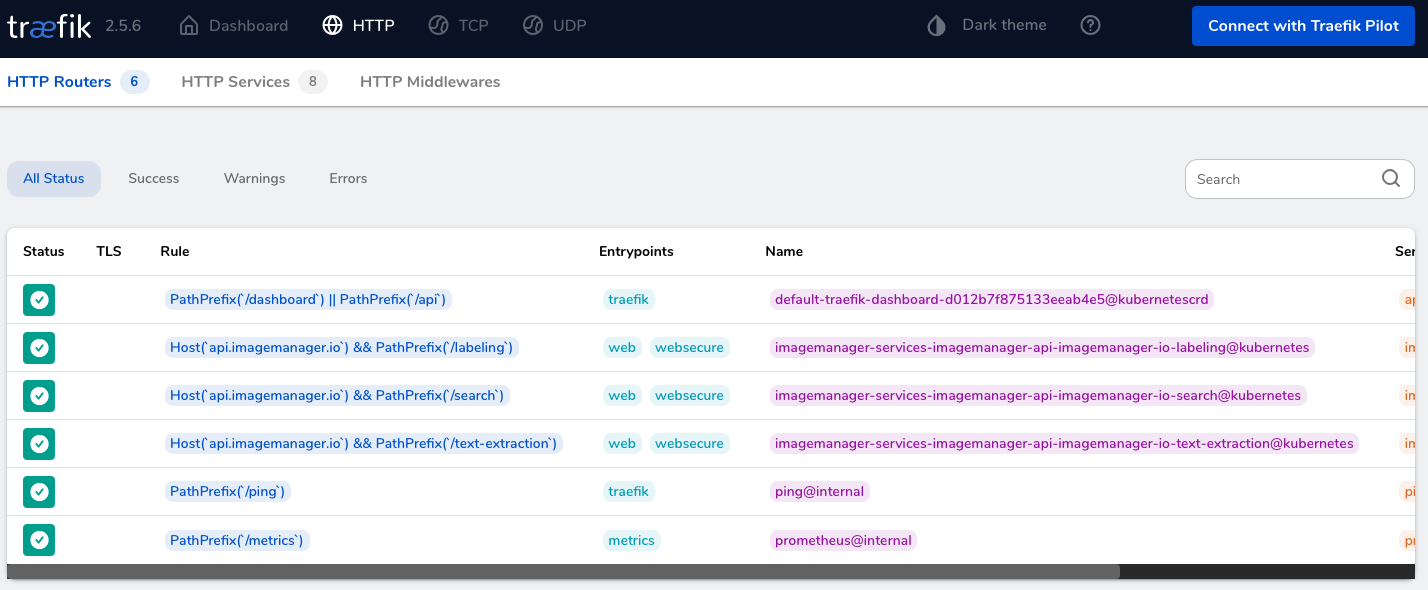
As you can see, Traefik has created three routers for us on the api.imagemanager.io host, and their paths match exactly what was provided in the Ingress spec. If you scroll to the right a bit, to the Service column, you’ll see the Service backends the routers have been assigned on the given paths.
Clicking the first api.imagemanager.io router entry will give you a more detailed view of this router, mentioning its entry points – corresponding to the endpoints in the Traefik LoadBalancer Service – as well as the Service backend traffic coming in on those endpoints will be routed to:
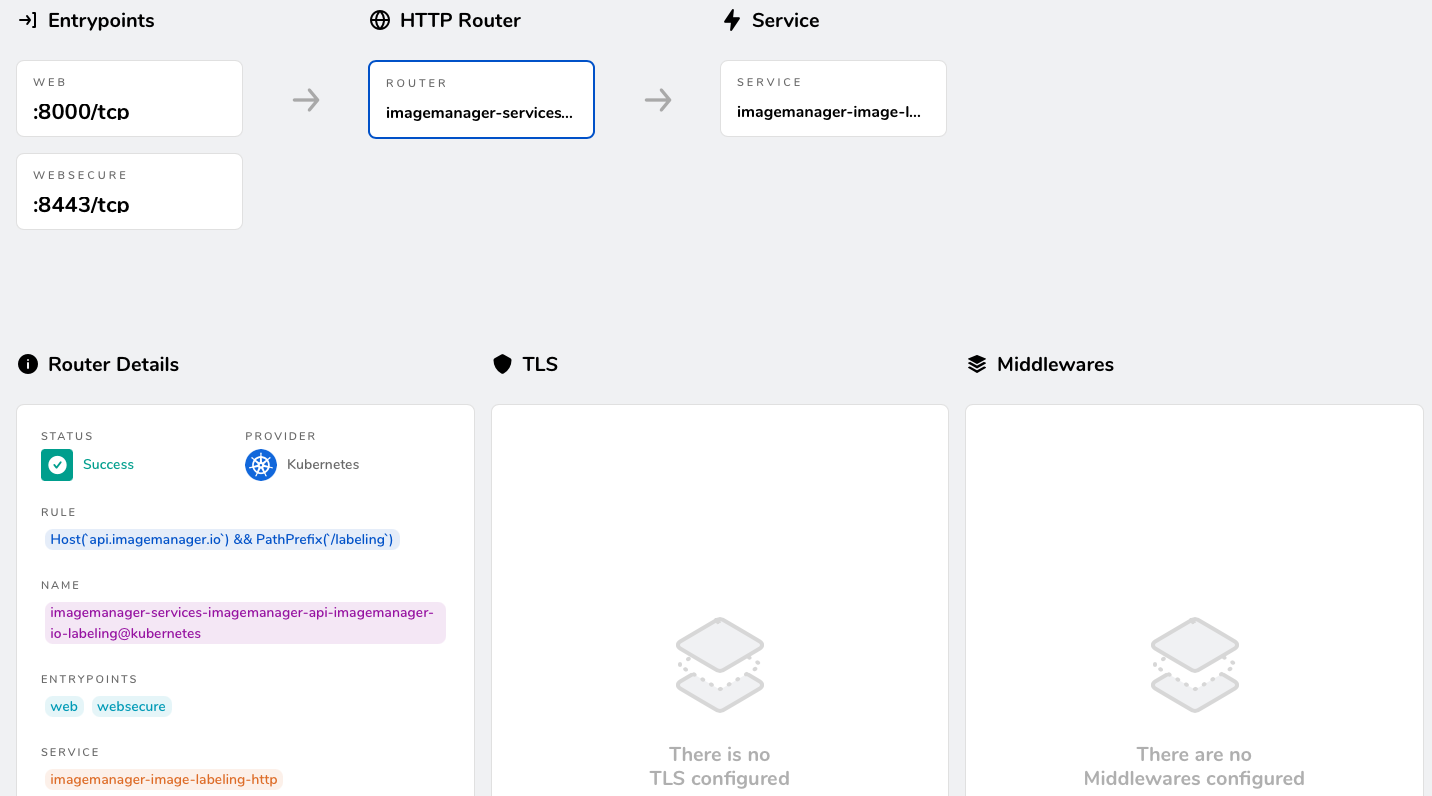
Next, click the orange box in the Service section in the lower-left corner (in my case, it’s labeled imagemanager-image-labeling-http):
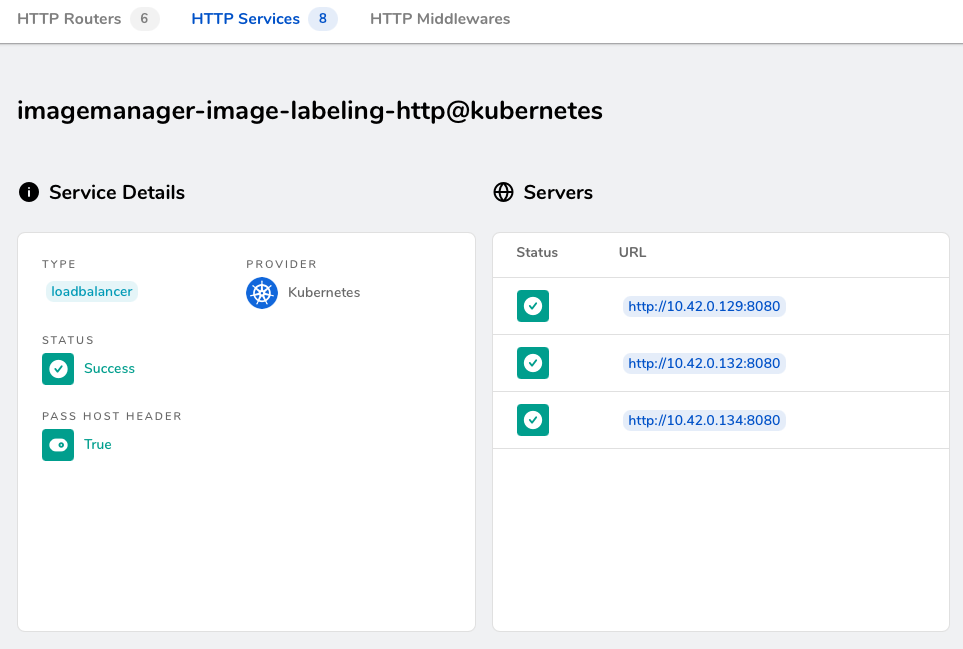
The most interesting part in here is the list of Server endpoints – as it happens, each of those entries corresponds to one image-labeling Pod by means of its IP address and the exposed port:
$ k -n imagemanager --selector="app=image-labeling" get pod -o custom-columns="IP:.status.podIP,PORT:.spec.containers[0].ports[0].containerPort"
IP PORT
10.42.0.132 8080
10.42.0.129 8080
10.42.0.134 8080
Although there are some Traefik-specific concepts in here, this should nicely outline the general path a request takes from hitting the Ingress Controller all the way to arriving at its desired workload. In the upcoming section, we’re going to issue a couple of requests against our demo workloads, and I’m going to use one of them as an example to highlight the request path.
Invoking Workloads
Let’s now issue some queries against our paths on api.imagemanager.io. Recall that the imaginary developer team have created three paths to be queried:
/labeling/search/text-extraction
Let’s invoke the first one with a simple curl command:
$ curl http://api.imagemanager.io/labeling
If the response you’re now seeing is *Busy image labeling noises*, everything works as expected! This means we can query the other workloads in the same way:
# Targeted workload is the 'image-search' set of Pods
$ curl http://api.imagemanager.io/search
*Busy image search noises*
# Targeted workload is the 'image-text-extraction' set of Pods
$ curl http://api.imagemanager.io/text-extraction
*Busy text extraction noises*
I’m going to use this last request to outline all steps it takes until hitting its desired workload in the cluster:
- DNS outside the cluster translates the request sent to the
api.imagemanager.iohost name to the external IP of the Ingress Controller’sLoadBalancerService (10.211.55.6, in my case), thus, the request reaches the Ingress Controller. (You can see this very nicely if you run thecurlcommand in verbose mode.) - The Ingress Controller, acting on OSI layer 7, peeks into the request’s header, sees that the requester would like to reach the
/text-extractionpath on theapi.imagemanager.iohost, and matches this against the set of routing rules established by all Ingress specs in the cluster this Ingress Controller is responsible for. In our case, so far, there is only one Ingress resource, and it contains threePrefix-type path rules for theapi.imagemanager.iohost, so the Ingress Controller will compare the requested path with the rule paths, and decide the request has to go to the backend Service defined for the/text-extractionrule. - The request hits the
image-text-extractionService, which knows all Pods it can send traffic to by means of its label selector, so it will forward the request to one of those Pods, where it can finally be processed.
To wrap up this section, let’s make small detour and look at what happens when things don’t go so smoothly, i.e. you need to troubleshoot one of the paths defined in the Ingress spec. To simulate a misconfiguration that causes no Pods to be available to serve a request, let’s scale down the Deployment for the image-text-extraction workload to zero.
$ k -n imagemanager scale deployment image-text-extraction --replicas=0
deployment.apps/image-text-extraction scaled
What happens if we now send a request to the /text-extraction path?
$ curl -v http://api.imagemanager.io/text-extraction
404 page not found
The response shown in this case varies between Ingress Controllers, but you’ll see some kind of message indicating the workload is not available either way – in Traefik’s case, the Controller simply returns HTTP 404. No matter what Ingress Controller you use, though, its logs are always a great way to kick off the troubleshooting journey, so let’s check what the traefik Pod has to say:
$ k logs traefik-7c48dbf949-zl47f
...
time="2022-02-04T16:23:46Z" level=error msg="Skipping service: no endpoints found" namespace=imagemanager ingress=imagemanager-services serviceName=image-text-extraction servicePort="&ServiceBackendPort{Name:http,Number:0,}" providerName=kubernetes
Kudos to the Traefik team for providing descriptive error messages – this particular line informs us no endpoints have been found for one of the Services defined as a backend, and it tells us the namespace, the Ingress object containing the backend definition in question, the Service name, and even the Service port. Awesome! This is a very important clue, so let’s check the list of endpoints for this particular Service:
$ k -n imagemanager describe svc image-text-extraction
...
Endpoints: <none>
...
# Comparison using Service 'image-labeling'
$ k -n imagemanager describe svc image-labeling
...
Endpoints: 10.42.0.129:8080,10.42.0.132:8080,10.42.0.134:8080
...
So, the reason we received HTTP 404 in our earlier request is there are no endpoints to serve the request. Let’s scale the image-text-extraction Deployment back up again and wait for the Pods become ready:
$ k -n imagemanager scale deployment image-text-extraction --replicas=3
deployment.apps/image-text-extraction scaled
$ watch kubectl -n imagemanager get pod --selector="app=image-text-extraction"
Every 2.0s: kubectl -n imagemanager get pod --selector=app=image-text-extraction
NAME READY STATUS RESTARTS AGE
image-text-extraction-85f69c4d7d-htgft 1/1 Running 0 117s
image-text-extraction-85f69c4d7d-4qgz7 1/1 Running 0 117s
image-text-extraction-85f69c4d7d-b2bhn 1/1 Running 0 117s
Finally, let’s send another request to the /text-extraction path:
$ curl http://api.imagemanager.io/text-extraction
*Busy text extraction noises*
As you’d expect, the endpoint is back up again. Hooray!
Ingress And Namespace Isolation
The most important caveat to be aware of on the user side of Ingress is, in my opinion, the fact that Ingress can, by design, circumvent namespace isolation, and I’d like to make this point using another example. (This example is where the second manifests file I’ve created comes in, which you can find here).
Let’s imagine another team of developers in the same company was told by management to implement a microservices-based application for managing personal notes. Let’s further imagine the team use a setup quite similar to the imagemanager team: They’ve create a Deployment object to manage their first workload, the notes-search microservice, and – because they would like to invoke it from outside the cluster – a Service and an Ingress object, along with a Namespace to encapsulate everything. Here’s the Ingress spec they’ve come up with:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: notesmanager-services
namespace: notesmanager
annotations:
traefik.ingress.kubernetes.io/router.entrypoints: web, websecure
spec:
rules:
- host: api.notesmanager.io
http:
paths:
- path: /search
pathType: Prefix
backend:
service:
name: notes-search
port:
name: http
Let’s apply the entire file and see what happens:
$ k apply -f https://raw.githubusercontent.com/AntsInMyEy3sJohnson/blog-examples/master/kubernetes/workload-reachability/deployments-with-ingress-2-notesmanager.yaml
namespace/notesmanager created
deployment.apps/notes-search created
service/notes-search created
ingress.networking.k8s.io/notesmanager-services created
A new router item should now pop up in the Traefik dashboard (the port forwarding command from earlier on to expose said dashboard should still be running):
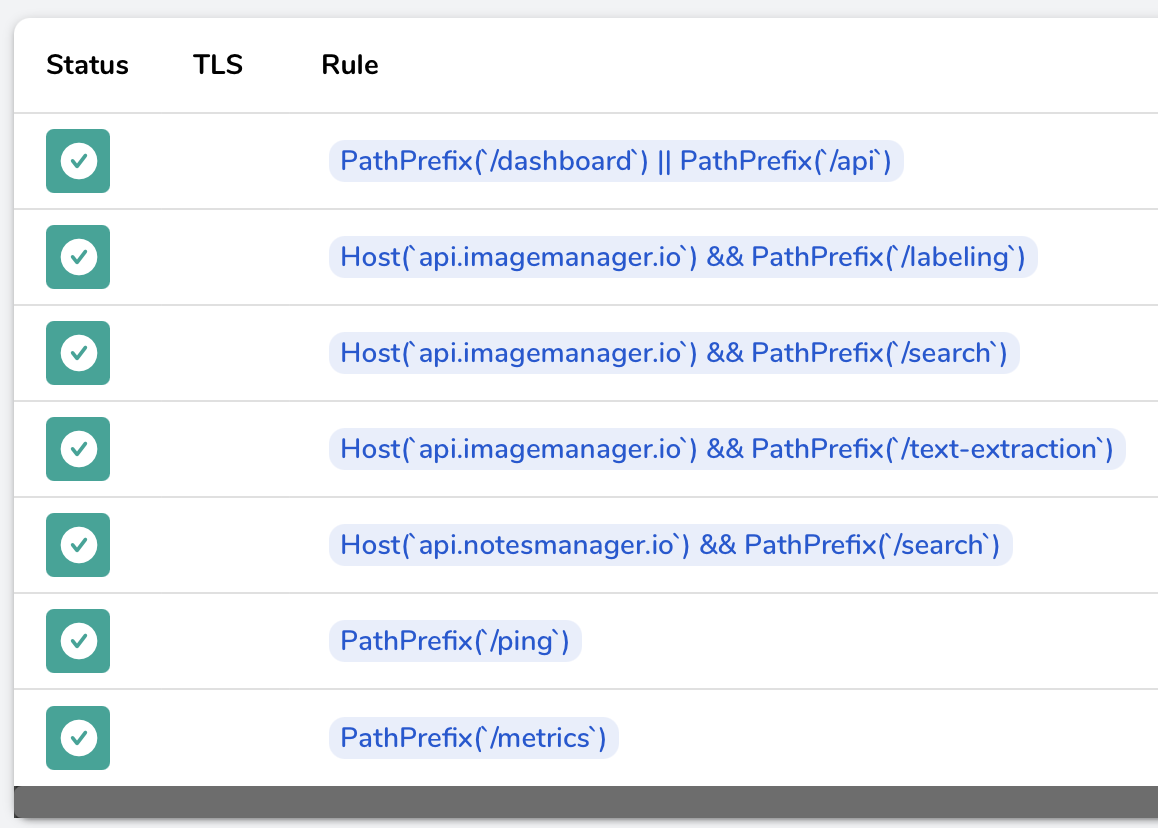
Indeed, a new item has appeared, so the team can now query their workload from outside the cluster:
# (Will only work if 'api.notesmanager.io' entry was added to /etc/hosts file in scope of preparation work)
$ curl http://api.notesmanager.io/search
*Busy note searching noises*
(From here on, we won’t need access to the Traefik dashboard anymore, so you can now go ahead and close the corresponding terminal.)
So far, so good – no problems until here. Let’s now go a bit further with the example scenarios and assume both teams have implemented login functionality which they would like to use as part of an API gateway they’re going to implement. Further, we assume their company, Awesome Company Inc., already have a well-established host name for this kind of functionality, namely, apps.apigateway.awesomecompany.io, and that both teams would like to use the /login path to host their login services. (You can find another manifests file for this scenario here in case you want to following along.)
Here are the Ingress specs both teams have come up with:
# ImageManager platform
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: imagemanager-login
namespace: imagemanager
annotations:
traefik.ingress.kubernetes.io/router.entrypoints: web, websecure
spec:
rules:
- host: apps.apigateway.awesomecompany.io
http:
paths:
- path: /login
pathType: Prefix
backend:
service:
name: login
port:
name: http
---
# NotesManager platform
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: notesmanager-login
namespace: notesmanager
annotations:
traefik.ingress.kubernetes.io/router.entrypoints: web, websecure
spec:
rules:
- host: apps.apigateway.awesomecompany.io
http:
paths:
- path: /login
pathType: Prefix
backend:
service:
name: login
port:
name: http
The problem is the teams use the same host-path combination, and because they don’t know about one another, they both happily submit their Ingress spec to the API server of the same Kubernetes cluster they both work on without suspecting anything. Why is this a bad idea? Let’s find out by applying the manifests file and curl the host-path combination in question:
# Apply manifests
$ k apply -f https://raw.githubusercontent.com/AntsInMyEy3sJohnson/blog-examples/master/kubernetes/workload-reachability/deployments-with-ingress-3-ingress-conflicts.yaml
# curl host-path combination
# (Works only if host name was added to /etc/hosts file)
$ while true; do curl http://apps.apigateway.awesomecompany.io/login ; sleep 2; done
Performing login for NotesManager platform
Performing login for NotesManager platform
Performing login for NotesManager platform
Performing login for NotesManager platform
Performing login for ImageManager platform
Performing login for ImageManager platform
Performing login for ImageManager platform
Performing login for ImageManager platform
Performing login for NotesManager platform
Performing login for NotesManager platform
...
As you can see, the Ingress Controller alternates between the two available backends. The underlying design characteristic of Ingress causing this is that if two or more Ingress objects contain conflicting host-path configurations, the behavior is undefined, so it is up to the Ingress Controller to decide what to do about it. The Kubernetes API, on the other hand, will not reject conflicting Ingress configurations (given that the spec’s Yaml is correct) because it has itself no idea about the notion of conflicting in the context of Ingress, so for our two imaginary teams of developers, it’s quite hard to spot the issue – all they see is their Ingress has been created successfully and that some login requests make it to the corresponding workload, while others seem to magically disappear into oblivion…
A way to tackle this challenge is to very carefully communicate the Ingress resources in use and establish guidelines around the usage of host names and paths within an organization (or at least the relevant teams), but that’s of course easier said than done. Ingress is a complex topic still under active development, and the example introduced above is one area where this complexity shows.
Cleaning Up
You can clean up all resources created in scope of this blog post from your k3s cluster by issuing the following command (regardless of how far you followed along using the manifest files, this command will delete all created namespaces and, with them, all resources existing therein):
$ k delete -f https://raw.githubusercontent.com/AntsInMyEy3sJohnson/blog-examples/master/kubernetes/workload-reachability/deployments-with-ingress-3-ingress-conflicts.yaml
namespace "imagemanager" deleted
deployment.apps "login" deleted
service "login" deleted
ingress.networking.k8s.io "imagemanager-login" deleted
namespace "notesmanager" deleted
deployment.apps "login" deleted
service "login" deleted
ingress.networking.k8s.io "notesmanager-login" deleted
If you would like to uninstall Traefik v2 as well, you can do so simply by running helm uninstall traefik.
In case you want to delete the k3s cluster altogether, the best way to accomplish this is by running the k3s uninstall script, k3s-uninstall.sh, located in /usr/local/bin.
Finally, don’t forget to wipe the host names added in scope of the preparation work from your machine’s /ect/hosts file.
Summary
Ingress addresses the challenge of exposing many workloads running in a Kubernetes cluster to the external world by acting as a single, central entry point into the cluster responsible for routing requests to the desired target workloads. The starting point for this idea is the Ingress specification – as a native Kubernetes object like any other, it contains the declarative set of routing rules and all corresponding configuration, but very much unlike other Kubernetes resources, another component – the so-called Ingress Controller – is necessary to act on the Ingress specs. This component’s job is to make sense of all Ingress specs present in the cluster (or those it is responsible for, anyway), thus acting either as a load balancer, or a reverse proxy, or both. The immense complexity and sheer number of use cases load balancers and reverse proxies can fulfil is the reason Kubernetes does not contain a default Ingress Controller.
One limitation of Ingress is that it can – as of today – only process HTTP and HTTPS traffic because, in order to fulfil its sophisticated routing tasks, it has to peek inside requests and thus work on layer 7 of the OSI model. This is why for exposing non-HTTP(S) workloads outside of the cluster, NodePort and LoadBalancer Services are still the go-to solution.
The Ingress specification allows teams to define path-based routing rules – most often with a given host name those paths should be exposed on – along with corresponding backends that requests on those paths should be routed to. This allows teams of developers to expose many workloads on a single host name while utilizing only a single LoadBalancer Service.
The concept of many entities located in different namespaces – the Ingress specs – and a cluster-central entity to act on those specs – the Ingress Controller – breaks the idea of namespace isolation and thus bears the potential of causing cross-namespace conflicts. For example, if two or more Ingress specs in different namespaces employ conflicting or overlapping host-path combinations, the behavior is undefined, and it is up to the Ingress Controller to decide how to handle the conflicts. The Ingress Controller used in scope of this blog post, Traefik v2, will alternate between the available backends, for example. To tackle this challenge, guidelines must be established in an organization on how to handle cross-namespace referencing of global resources such as the name of a network host.
