On Modelling Clay And Glue

Labels are a fundamental concept in Kubernetes – they provide users with the flexibility to group their applications as they see fit, and they are the reason why Kubernetes can be a decoupled system of many components working together. This blog post will introduce you to the necessity for flexibility, the basics of labels, and how to use them.
Worry not, dear reader, despite the heading of this blog post indicating otherwise for added catchiness, we are still in the Kubernetes world! The following blog post will introduce you to something called labels (and a bit of annotations, too), and in so doing uncover the mystery of just what Kubernetes might have to do with modelling clay and glue.
- The Challenge: Software Evolves
- The Solution: Labels
- Working With Labels
- Labels Versus Annotations
- Wrap-Up
The Challenge: Software Evolves
To motivate the use of labels, let’s take a short look at the evolution of an application’s source code. If you’ve ever written any piece of software beyond the scope of a small example or prototype, I’m sure you’ll have noticed the code you write quite naturally establishes different responsibility groups as it grows. You probably also faced the challenge of grouping your code into various layers of abstraction according to those responsibilities. As your application then grew further, you may have had to enter into a loop of arranging and rearranging – or refactoring – those abstraction layers for them to form loosely coupled and cohesive building blocks. An application’s source code, then, seems to be dynamic rather than static – an idea that David Thomas and Andrew Hunt paraphrased very nicely in their fantastic book The Pragmatic Programmer: Rather than construction, software is more like gardening.
Let’s now imagine large software systems that consist of n applications and maybe some infrastructure components (like databases, message queues, and so on) supporting them. If the insides of those applications evolve, it seems obvious the entire software system will evolve, too (or, at least, you’d probably be in for a nasty surprise if you assumed, and planned for, the contrary). Thus, the platform running that software system – say, a container orchestration platform like Kubernetes – must be flexible enough to allow for such evolution to take place because any assumptions it makes about the structure of a software system will often clash with reality, thus imposing a limit on how the engineers think about their software system.
I currently develop a small monolith that might serve as an interesting example to highlight the point made above. For now, there’s only this single application deployed to Kubernetes, but in order to avoid monolithic hell, I’ll have to slice it into microservices at some point. I’m not sure yet on the strategy to apply for slicing, but – without going into too much detail on what the application does just yet – the smallest set of microservices will probably contain one service for image labeling, one for searching images, and another one dedicated to persistence. Add a database and a message queue and you get a software system whose components are highly individual to the functionality of that particular system. It’s obvious now the platform to run the system must allow for arbitrary service and hierarchy structures in order to enable the system to grow and flourish according to the needs dictated by new requirements and ideas – and not by the limits of the platform running it.
The Solution: Labels
Kubernetes labels provide the kind of flexibility users need to freely organize the components of their software systems. They are key-value pairs that you can attach to all Kubernetes objects and that hold identifying information about the object they have been attached to. For example, if you wanted to add identifying information to a Pod, you could use the following labels:
apiVersion: v1
kind: Pod
metadata:
name: my-labeled-pod
labels:
stage: dev
group: persistence
app.kubernetes.io/name: some-app-dealing-with-persistence
This shows that labels have very simple syntax – both the keys and the values are simply strings – and that the label key can contain an optional prefix, separated from the label’s name by a slash.
Although the syntax is simple, there are a couple of restrictions to be aware of:
- If a prefix is specified (here:
app.kubernetes.io), it must be a valid DNS subdomain not langer than 253 characters - The name of a label (here:
stage,group, andname) is mandatory - Both the label’s name and value can be up to 63 characters long and must consist of alphanumeric characters plus dots, underscores, and dashes, but the latter three must not appear at the beginning or the end of the string
Working With Labels
There are two parts to working with labels: Applying them to objects, and selecting objects based on applied labels by means of label selectors.
Applying Labels
A simple file containing a couple of Pod manifests that demonstrate how to use labels to group objects awaits you over on GitHub. Three labels have been applied to those pods:
app.kubernetes.io/namegroupuser
The file defines four Pods in total, and the following excerpts show the labels that have been applied to group them:
Pod 1:
metadata:
name: persistence-app-instance-1
namespace: labelled-pods-example
labels:
app.kubernetes.io/name: persistence-app
group: persistence
user: dave
Pod 2:
metadata:
name: persistence-app-instance-2
namespace: labelled-pods-example
labels:
app.kubernetes.io/name: persistence-app
group: persistence
user: mary
Pod 3:
metadata:
name: another-persistence-app-instance-1
namespace: labelled-pods-example
labels:
app.kubernetes.io/name: another-persistence-app
group: persistence
user: dave
Pod 4:
metadata:
name: search-app-instance-1
namespace: labelled-pods-example
labels:
app.kubernetes.io/name: search-app
group: search
user: mary
Once the manifests file has been applied using the kubectl apply command, four Pods will spawn and become ready. According to their labels, they form the following groups:
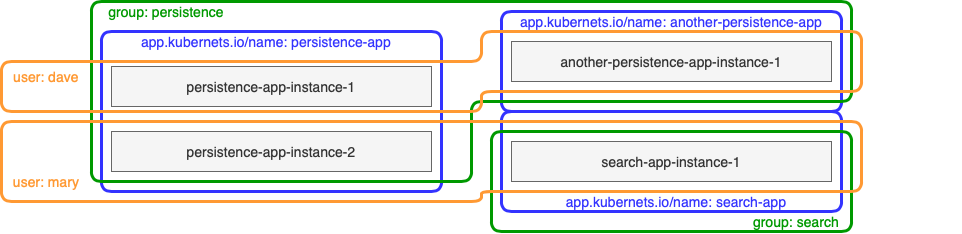
Recalling that labels can be applied to any kind of Kubernetes object, it’s easy to imagine how they can be used to make sets of objects form any kind of group or hierarchy the user desires. This fundamental quality of labels is the source for Kubernetes’ flexibility that lets users impose the object groupings that work best for them (and, incidentally, also motivated the use of the word modelling clay in this blog post’s heading).
Selecting Objects Using Label Selectors
You probably guessed that label selectors make up for the second part of this blog post’s heading, the glue. Labels relate objects to one another, and to make the relations thus imposed manifest, label selectors are used to select a set of target objects based on their labels.
Let’s demonstrate this by formulating some selection queries against the Pods previously created. First of all, we can reveal the labels our Pods carry using the --show-labels option on the kubectl client:
$ alias k=kubectl
$ k -n labelled-pods-example get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
persistence-app-instance-2 1/1 Running 0 3m44s app.kubernetes.io/name=persistence-app,group=persistence,user=mary
persistence-app-instance-1 1/1 Running 0 3m44s app.kubernetes.io/name=persistence-app,group=persistence,user=dave
another-persistence-app-instance-1 1/1 Running 0 3m44s app.kubernetes.io/name=another-persistence-app,group=persistence,user=dave
search-app-instance-1 1/1 Running 0 3m43s app.kubernetes.io/name=search-app,group=search,user=mary
This gives us something to work with. The following label selector will deliver all Pods belonging to Dave:
$ k -n labelled-pods-example get pod --selector "user=dave"
NAME READY STATUS RESTARTS AGE
persistence-app-instance-1 1/1 Running 0 8m11s
another-persistence-app-instance-1 1/1 Running 0 8m11s
Similarly, to retrieve all Pods of the persistence-app application:
$ k -n labelled-pods-example get pod --selector "app.kubernetes.io/name=persistence-app"
NAME READY STATUS RESTARTS AGE
persistence-app-instance-2 1/1 Running 0 10m
persistence-app-instance-1 1/1 Running 0 10m
Label selectors can also be combined, enabling us to formulate more complex queries. For example, here’s a query to select all of Mary’s Pods in the search group (only one Pod in this example):
$ k -n labelled-pods-example get pod --selector "user=mary,group=search"
NAME READY STATUS RESTARTS AGE
search-app-instance-1 1/1 Running 0 14m
Finally, let’s do a last query that makes use of the in operator (see table below):
$ k -n labelled-pods-example get pod --selector "user=mary,group in (persistence,search)"
NAME READY STATUS RESTARTS AGE
search-app-instance-1 1/1 Running 0 16m
persistence-app-instance-2 1/1 Running 0 16m
The following table lists all possible operators you can use to phrase selector queries:
| Operator | Description |
|---|---|
mykey | mykey is set |
!mykey | mykey is not set |
mykey=myvalue | mykey is equal to myvalue |
mykey!=myvalue | mykey is not equal to myvalue |
mykey in (myvalue1, ..., myvalueN) | mykey is equal to one of the given values |
mykey notin (myvalue1, ..., myvalueN) | mykey is not equal to any of the given values |
Although there might be some use cases requiring you to work with label selectors yourself, their most important use is in how Kubernetes objects find other objects they are responsible for or have some other relationship with. For example, a Service object finds the Pods it must load-balance traffic across by means of label selectors. The combination of labels and label selectors thus not only brings a lot of freedom to Kubernetes’ users, but also allows Kubernetes itself to be a flexible system of highly decoupled components.
Labels Versus Annotations
Annotations are also key-value pairs you can apply to Kubernetes objects, but there is an important distinction to labels: While the latter hold identifying metadata – after the previous paragraph, it’s obvious why this meta information is referred to as identifying –, annotations provide a place to store metadata that is merely descriptive in nature, providing additional information about the object they have been attached to.
For example, think of the following types of information:
- The name of the team or user that is responsible for an object
- The tier or group the object fits into within a larger software system
- A commit number identifying the state of the object’s application (in case of a Pod)
- The Base64-encoded representation of an icon or small image to display about the object in a GUI
The former two may be important to identify the objects in question, so you might add them as labels. The latter two, on the other hand, may provide other tools or libraries with information they need about the object to fulfil their purpose, so it’s probably more desirable to add them as annotations. As a general rule of thumb, it’s often a good idea to add a piece of information as an annotation first and transform it to a label if the need arises.
Wrap-Up
Applications evolve over time, so it’s natural for entire software systems – composed of many applications working together – to evolve, too. Labels provide immense freedom to Kubernetes’ users as they let them group and align the components of their software systems in the way that works best for the specific needs of those systems. Kubernetes itself requires this kind of flexibility for its own components, too, and labels enable them to form a loosely coupled system. All of this is only possible in combination with label selectors, which provide a means to act on previously applied labels – labels establish object relations, but it’s the label selectors that make those relations usable. Finally, annotations are similar to labels in that they, too, are key-value pairs that hold meta information, but that meta information is merely descriptive in nature, rather than identifying. Thus, labels and annotations serve two distinctly different purposes.
